
Migrating from Hadoop/Spark to Snowpark
For one of my client I performed a migration from an on-premise data platform to a data platform on AWS using Snowflake.
This blog post is here to explain how we split this task in smaller ones, through which stages we went and what were the issues. I will not go into details regarding code conversion but this part for some other posts about this.
Introduction
For this project I was acting as Lead Data Engineer and was in charge of designing the new architecture and migrating from Hadoop on-premise to the cloud. The main focus was on migrating fast even if it means not using the new features available on AWS or Snowflake.
Regarding the timeline the design was done end-of-year 2022 and the deployment was done in 3 months between Q1 and Q2 2023.
The team was composed of:
- 1 Lead and 1 Senior Data Engineers
- 2 Confirmed Data Engineers
- 4 Data Analysts
As we had to ensure that the business as usual was still running we only had 1/3 of the team working on the migration except for the last week where everybody helped.
Regarding data sizes, we had several tables holding billions of rows and hundreds of Go, the total size being between 2 to 3 To. With size being heavily skewed, toward several very big tables and a few smaller ones.
The tech stack
The biggest key-elements defining our stack was that we didn't want to do maintenance on our tool anymore, we needed, notebooks, pyspark compatibility, easy scalability and make the migration the easiest possible.
The design was composed of AWS components and Snowflake as Warehouse. We also decided to use Databricks for the notebooks while waiting for Snowflake notebooks to be ready. It was also a simple way for us to still have a Spark cluster easily accessible if we were not able to run our PySpark code on Snowpark (even if the sales people say so, you better check)
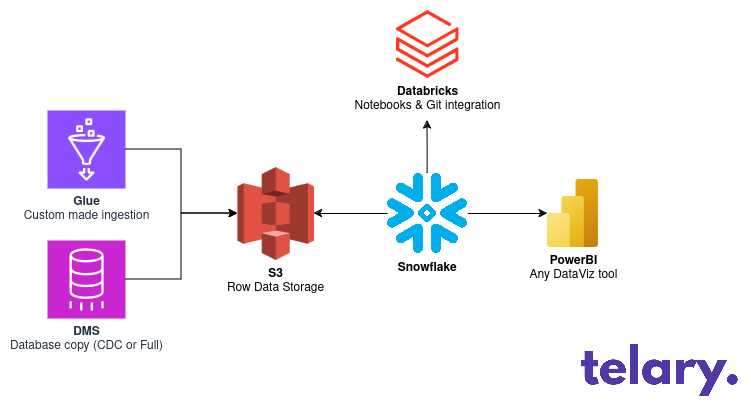
State of Snowflake
In end of 2022 the version 1.0.0 of Snowpark for Python was released. We started working with the 1.1.0, the technology was good enough even if we found some small bugs in our testing. The only issue we had was that we didn't find that much examples on the internet and especially almost no issues about Snowpark on StackOverflow.
In june 2024 Snowflake notebooks are available, we still found some bugs so I decided it wasn't mature enough compared to Databricks yet.
How did we tackle the migration?
Here are the big steps we did.
Remove the technical uncertainty
The first step we did was identify the complex and important parts of our code.
The biggest worry I had was around some very complex window functions in the most important table in our BI, so we decided first to convert this Pyspark code to Snowpark. We did it by hand because it was supposed to not be that much code change (Indeed it was quick), the long part was the QA time.
Details on the code conversion
Regarding the code conversion & rewrite you can take a look at the details in this 3 blog posts to see some really detailed explanations. Some things are probably smoother now because Snowpark got more mature.


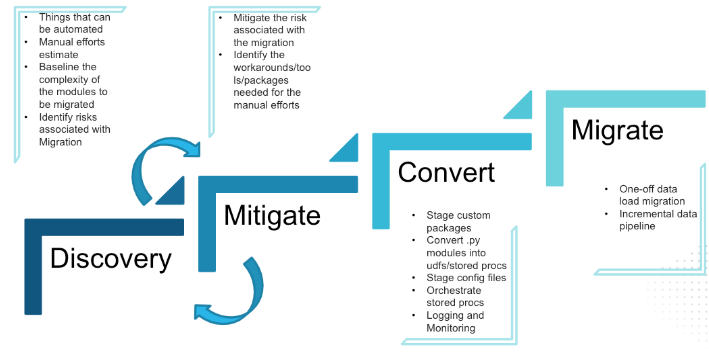
Migrate the simplest component
Then I migrated the most simple gold layer table, this was a way for me to ensure that the End to End process was working and that we didn't miss anything. The complex part was not about the Snowpark but about ensuring that from ETL to DataViz all the components were connected and working.
Share the work and do the remaining parts
This is were the real migration begins, we're confident we can do it thanks to the previous steps now it's time to do it.
Based on the work in the 2 previous steps we estimated the workload for all the other spark jobs we had, around 30 of them were top priority. The remaining reports and jobs would be done at a later time.
We tracked our progression in a spreadsheet, because we wanted to track a lot of things and don't really want to loose time customizing Jira tickets but it's probably better to do it in a dedicated tool.
The status we wanted to track for each spark jobs were:
- Priority to help us understand on what we need to focus
- Migrated on Snowpark yes / no
- Tested by the data engineering team
- Tested by the data analysis team
- Data Viz tool adaptation done: Is the table outputted by the job ready to use? Or are the adaptation required done?
- Comments: used to track regression, row count diffs and details we didn't want to forget
- Not implemented: this column was used to track how many fields were skipped in the migration some high complexity, low importance field were skipped and re-implemented at a later time.
Data Quality and Testing
Another challenge was to be able to compare the 2 data warehouses. The on-prem one was still running and data were always changing. So we decided to do a data copy and move it to the cloud and compare it using best-effort testing.
We checked for:
- Row count
- and columns available
But that's obviously not enough, we needed something automated or fast enough with the constraint that we couldn't have exactly the same input data in the cloud and on-prem thus couldn't have the same output. The specificity of the data was also that we had to run the tests on the full history of the data because some weird behavior are only seen in really old rows.
The solution was to explore the repartitions of the data for each columns
columns = df.columns
group_by_values = []
for col in columns:
group_by_count = df.groupBy(col).count().orderBy(col)
if "count" in group_by_count.columns:
group_by_count = group_by_count.withColumnRenamed("count", "COUNT")
if group_by_count.count() > 25:
count = group_by_count.count()
else:
count = group_by_count.toPandas().to_json()
count = json.dumps(json.loads(count), indent=2)
group_by_values.append(f"{col} - {count}")the output looked like this:
----------------------------------------------------------
MyJobOutput - OnPrem
filter = 2023-02-28 23:59:59 >= my_date_field >= 2013-02-01 00:00:00
----------------------------------------------------------
Columns
- col_1
- col_2
- col_3
----------------------------------------------------------
Cardinality
103275730
----------------------------------------------------------
GroupBy fields
col_20 - 104103
col_21 - 1486594
col_22 - {
col_22: {
0: null,
1: value_1,
2: value_2,
3: value_3,
4: value_4,
5: value_5
},
COUNT: {
0: 8031537,
1: 546,
2: 1380,
3: 335,
4: 227,
5: 2715205
}
}We ran it on Spark output and on Snowpark. It can be really slow obviously but it's not like you don't have any other things to do during a migration.
The cool thing about having a full text display is that we could use git diff to compare the results and visually (and easily) ensure that there are no changes or only expected ones.
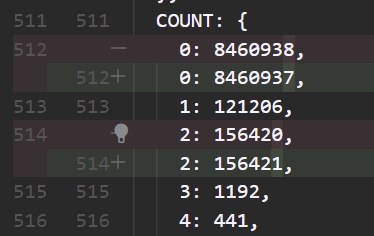
We did that for all the jobs, sometimes with several back and forth. We even found that we fixed some bugs during the migrations.
Pyspark / Snowpark incompatibilities
We faced some issues with the following Snowpark / Pyspark functions:
- Aggregations and alias used in aggregations: aggregations works nearly the same but the syntax can be a bit different, and you couldn't use alias in aggregate fields.
- Pivots: You can do the same tasks but the syntax will be a bit different.
- Concat / Concat_ws: This one is tricky, in Spark if you concat with a null value, the output is always null. Usually for this kind of situation you use concat_ws, BUT in snowpark if you're reading the documentation of concat_ws you can see, if any of the values is null, the result is also null.
+----+----+------+---------+
| a| b|concat|concat_ws|
+----+----+------+---------+
| 1| 2| 12| 12|
| 2|null| null| 2|
| 3| 4| 34| 34|
| 4| 5| 45| 45|
|null| 6| null| 6|
+----+----+------+---------+Example of concat in Spark
- Regex: regex_extract was replaced using a combination of join_table_function and split_to_table
Cost management
Regarding cost management, the biggest recommendation I could do is to split everything you can, having a single warehouse will lead to increased spending and reduce readability on your bills.
As you're not paying for a warehouse that is turned off, you should create some warehouse for your ETL, for your transformations, for your reports, for your data scientists workload...
This will lead to a sizing defined by the workload and will let you choose between horizontal and vertical scalability for each workload. For example your BI tool could use horizontal scalability and auto-scale if you have lots of users and your ETL should avoid using auto-scale to avoid variable costs for a predictable workload.
You can also go further and reduce the size of the warehouse. For example if your ETL use a big warehouse but it's only running during the night, you can run a SQL query to reduce its size to avoid mistakes of manually launching a costly instance.
The same recommendation works also for Users and Roles in Snowflake, create a dedicated user for each tools and the future you will thank you.
Last note
Snowflake sales people may say that the price increase of the computing is offset by the fact that you can use far smaller warehouse to run the same workload than you were using on Spark. It may be true, but if you have really computing intensive tasks using several hundreds Go of data, I would recommend to do some testings. If you blindly believe them you're the one taking the risks...
Conclusion
While not being 100% compatible, migrating from PySpark to Snowpark is perfectly doable and not that complicated, the biggest challenge is probably the QA part where you will have to ensure that all your jobs are still outputting the same results because most of the discrepancies we faced were silent and hard to find.
I think the migration was quite straightforward because we were using Spark an open source and widely established computing framework, if we had to migrate back from Snowpark and were using some Snowflake specific features the task would probably be more complex. Always keep in mind that you're safer from vendor locking when using SQL or Spark.
At Telary we tackle this kind of challenges but we also deploy data platforms from scratch, especially for Startup and Scaleup, we have quick execution and an ROI based approach, feel free to contact me https://www.linkedin.com/in/constant-deschietere/
or book a meeting 👇
